神经网络之优化器的妙用
加强对神经网络内部运行流程的理解有助于研究者和开发者训练神经网络。本文作者 Piotr Skalski 撰写了一系列文章介绍神经网络的奥秘,本文就是其中一篇,介绍了神经网络训练过程中的常见优化策略,并进行了分析和对比,包括梯度下降、小批量梯度下降、动量梯度下降、RMSProp、Adam 等。
之前的文章介绍了,我可以只使用 Numpy 来创建神经网络。这项挑战性工作极大地加深了我对神经网络内部运行流程的理解,还使我意识到影响神经网表现的因素有很多。精选的网络架构、合理的超参数,甚至准确的参数初始化,都是其中一部分。本文将关注能够显著影响学习过程速度与预测准确率的决策──优化策略的选择。本文挑选了一些常用优化器,研究其内在工作机制并进行对比。
注:由于我想覆盖的学习材料范围太大,因此文中未列出任何代码段。不过,大家可以在 GitHub 上找到所有用于创建可视化的代码。此外,我还准备了一些 notebook,帮助大家更好地理解本文所讨论的问题。
代码地址: https://github.com/SkalskiP/ILearnDeepLearning.py
优化
优化是不断搜索参数以最小化或最大化目标函数的过程。我们通常使用间接优化方法训练机器学习模型,选择一个评价指标(如准确率、精度或召回率)表明模型求解给定问题的优良程度。但是,我们一直在优化不同的成本函数 J(θ),希望最小化成本函数以改善评价指标。毫无疑问,成本函数的选择通常与需要解决的具体问题相关。本质上,这种「有意设计」表明我们与理想解决方案有多远。正如大家所知,这个问题相当复杂,可以再另写一篇主题文章。
沿途陷阱
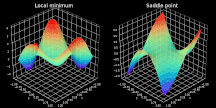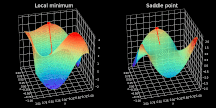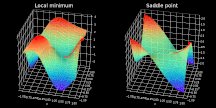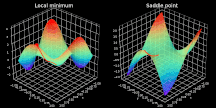
结果证明,寻找非凸成本函数最小值通常不太容易,本文应用高级优化策略去定位最小值。如果你学过微积分,就一定知道局部极小值──优化器极易落入的最大陷阱之一。对于那些还不了解局部极小值之美的读者,我只能说局部极小值是给定区域内函数取最小值的点集。如上图左半部分所示,优化器定位的点并非是全局最优解。
而「鞍点」问题则被人们认为更具挑战性。当成本函数值几乎不再变化时,就会形成平原(plateau),如上图右半部分所示。在这些点上,任何方向的梯度都几乎为零,使得函数无法逃离该区域。
有时候,尤其是在多层网络中,我们必须处理成本函数的陡峭区域。陡峭区域中的梯度增长迅速(也就是梯度爆炸)会引起大步跃迁,通常会破坏先前的优化结果。不过,该问题可以通过梯度裁剪轻松解决。
梯度下降
在学习高级算法前,我们先来了解一些基本策略。最直接有效的方法之一是向函数上当前点对应梯度的反方向前进,公式如下:
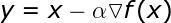
超参数 α 表示学习率,代表算法每次迭代过程的前进步长。学习率的选择一定程度上代表了学习速度与结果准确率之间的权衡。选择步长过小不利于算法求解,且增加迭代次数。反之,选择步长过大则很难发现最小值。具体过程见图 2,图中展示了不稳定的迭代过程。而选择合适步长后,模型几乎立即发现最小点。
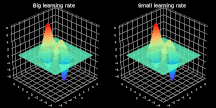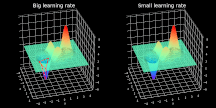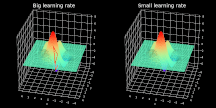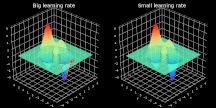
图 2. 大、小学习率条件下梯度下降过程的可视化。为了易于观察,图中仅展示了最后 10 步的可视化情况。
此外,该算法很容易受鞍点问题的影响。因为后续迭代过程的步长与计算得到的梯度成比例,所以我们无法摆脱 plateau。
最重要的是,算法由于每次迭代过程中都需要使用整个训练集而变得低效。这意味着,在每个 epoch 中我们都必须考虑所有样本,以确保执行下轮优化。对于只有几千个样本的训练集来说,这也许不是问题。但是,拥有数百万样本的神经网络才能表现最佳。基于此,每次迭代都使用全部数据集令人难以想象,既浪费时间又占用内存。上述原因致使纯粹的梯度下降无法应用于大部分情况。
小批量梯度下降
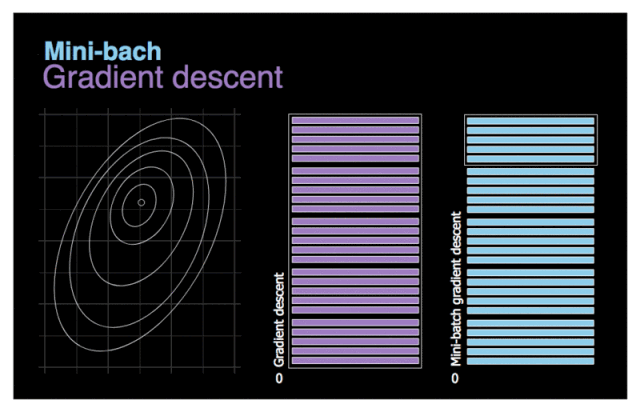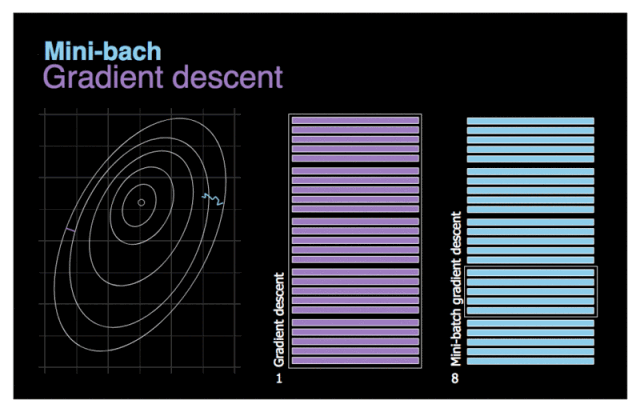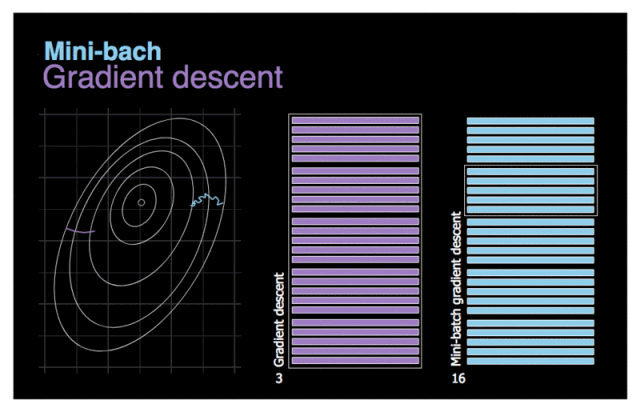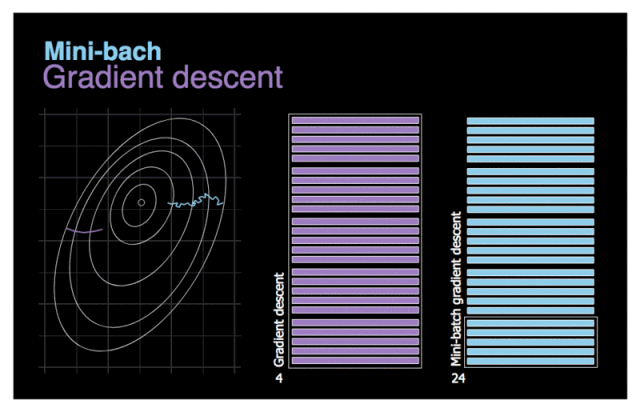
图 3. 梯度下降与小批量梯度下降对比图。
我们首先尝试解决上一节提到的最后一个问题──低效性。尽量向量化通过单次处理多个训练样本来加速计算,但在使用百万量级的数据集时优化过程还是需要花费很长时间。此处,我们试用一个简单的方法──将完整数据集切分成许多小批量以完成后续训练。小批量梯度下降的可视化动图见图 3。假设左图的等高线象征需要优化的成本函数。如图所示,由于新算法的待处理数据较少,它能够快速完成优化。我们再看看两个模型的移动轨迹对比。当噪音较少时,梯度下降采取较少步和相对较大的步长。另一方面,小批量梯度下降前进更频繁,但由于数据集的多样性,噪声更多。甚至可能在某次迭代过程中,算法移动的方向与预计方向相反。不过,小批量梯度下降通常一直朝向最小值移动。
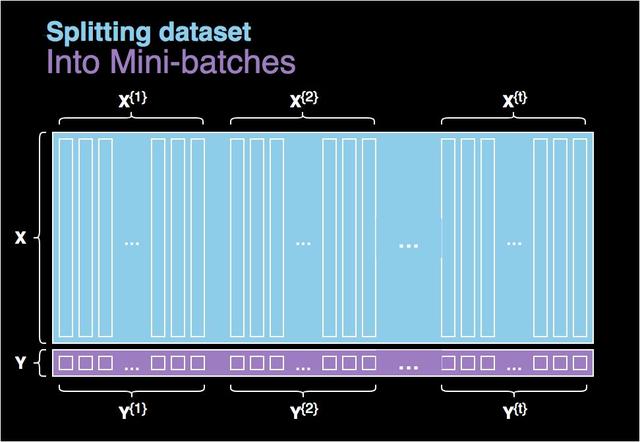
图 4. 将数据集划分为多个批量。
大家肯定想知道如何选择批量大小?以深度学习为例,批量大小通常不是绝对的,应参照具体情况。如果批量与整体数据集大小相等,那它就与普通梯度下降无异。另一方面,如果批量为 1,那么算法每次迭代仅适用数据集中的 1 个样本,这也失去了向量化的意义,该方法有时被称为随机梯度下降。实际情况下,我们通常会选择中间值──64 至 512 个样本。
指数加权平均
指数加权平均应用广泛,如统计学、经济学,甚至深度学习。即便给定点的梯度为 0,指数加权平均仍能持续优化,所以许多高级神经网络优化算法都采用此概念。
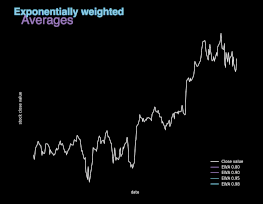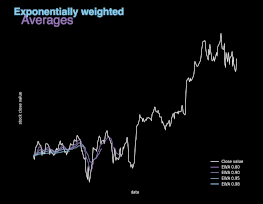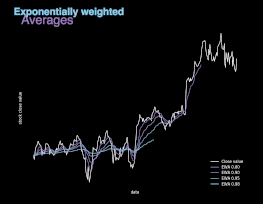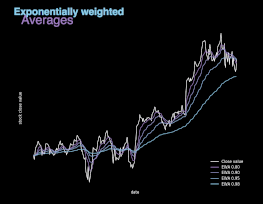
图 5. 不同 β值的指数加权平均(EWA)图示。
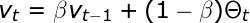
指数加权平均本质上是对之前的数值求平均值,避免局部波动,关注整体趋势。指数加权平均的计算公式如上所示,其中参数 β 控制待平均的数的范围。后续迭代过程中,算法将使用 1/(1 - β) 个样本。β 值越大,平均的样本数越多,图像越平滑。另一方面,图像缓慢右移是因为,平均时间范围较长会使指数加权平均适应新趋势较慢。如图 5 所示,股票实际收盘价与另外 4 条曲线展示了不同 β 值条件下的指数加权平均值。
动量梯度下降
动量梯度下降利用指数加权平均,来避免成本函数的梯度趋近于零的问题。简单说,允许算法获得动量,这样即使局部梯度为零,算法基于先前的计算值仍可以继续前进。所以,动量梯度下降几乎始终优于纯梯度下降。
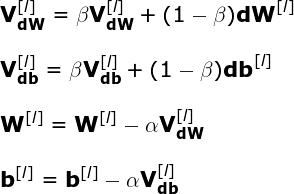
如以往一样,我们使用反向传播计算网络各层的 dW 和 db 值。然而,这次我们没有直接使用计算梯度来更新神经网络参数,我们首先计算 VdW 和 Vdb 的中间值。然后在梯度下降中使用 VdW 和 Vdb。值得注意的是,实现该方法需要记录迭代过程中的指数加权平均值。大家可以在 Github 中看到全部过程。

图 6. 动量梯度下降。
我们尝试想象下指数加权平均对模型行为的影响,再想象下成本函数的等高线。上图对比展示了标准梯度下降与动量梯度下降。我们可以看到成本函数图的形态使得优化非常缓慢。以股市价格为例,使用指数加权平均使得算法专注于未来走势而非噪声。最小值分量被放大,振荡分量逐渐消失。此外,如果后续更新过程中所得梯度指向类似方向,则学习率将增加,进而实现更快收敛并减少振荡。然而,动量梯度下降的不足之处在于,每当临近最小点,动量就会增加。如果动量增加过大,算法将无法停在正确位置。
RMSProp
RMSProp(Root Mean Squared Propagation)是另一种改善梯度下降性能的策略,是最常用的优化器。该算法也使用指数加权平均。而且,它具备自适应性──其允许单独调整模型各参数的学习率。后续参数值基于为特定参数计算的之前梯度值。
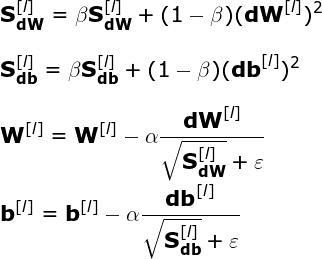
运用图 6 及上述公式,大家来思考下该策略背后的逻辑。顾名思义,每次迭代我们都要计算特定参数的成本函数的导数平方。此外,使用指数加权平均对近期迭代获取值求平均。最终,在更新网络参数之前,相应的梯度除以平方和的平方根。这表示梯度越大,参数学习率下降越快;梯度越小,参数学习率下降越慢。该算法用这种方式减少振荡,避免支配信号而产生的噪声。为了避免遇到零数相除的情况(数值稳定性),我们给分母添加了极小值 ɛ。
必须承认,在本篇文章的写作过程中,我有两次异常兴奋的时刻──本文所提及优化器的快速革新让我震惊不已。第一次是当我发现标准梯度下降和小批量梯度下降训练时间的差异。第二次就是现在,比较 RMSprop 与我知道的所有优化器。然而,RMSprop 也有缺点。由于每次迭代过程中公式的分母都会变大,学习率会逐渐变小,最终可能会使模型完全停止。
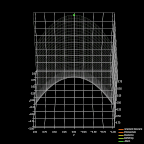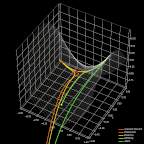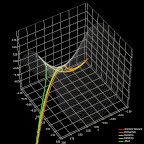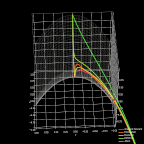
图 7. 优化器对比。
Adam
最后,我再说说 ADAM。与 RMSProp 类似,ADAM 应用广泛且表现不俗。它利用了 RMSProp 的最大优点,且与动量优化思想相结合,形成快速高效的优化策略。上图展示了本文讨论的几类优化器在处理函数困难部分的优化过程。Adam 的优异表现一目了然。
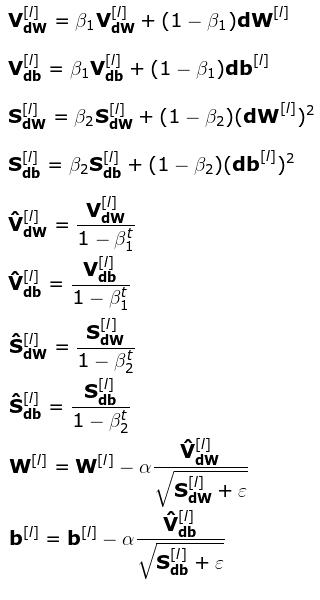
不幸的是,随着优化方法有效性的提高,计算复杂度也会增加。上面列了 10 个描述优化过程单次迭代的矩阵公式。我知道那些数学基础薄弱的读者情绪肯定不高。但是不要担心,它们并不是什么新内容。这里的公式和前文给出的动量梯度下降和 RMSProp 一样。不过这里我们需要一次性运用这两个策略的思路。
总结
希望本文能够深入浅出地解释所有难点。在这篇文章的写作过程中,我明白了选择合适优化器的重要性。理解上述算法才能自如地运用优化器,理解每个超参数如何改变整个模型的性能。
原文链接:https://towardsdatascience.com/how-to-train-neural-network-faster-with-optimizers-d297730b3713